【データ分析】データウェアハウス、データレイク、データレイクハウスの違い
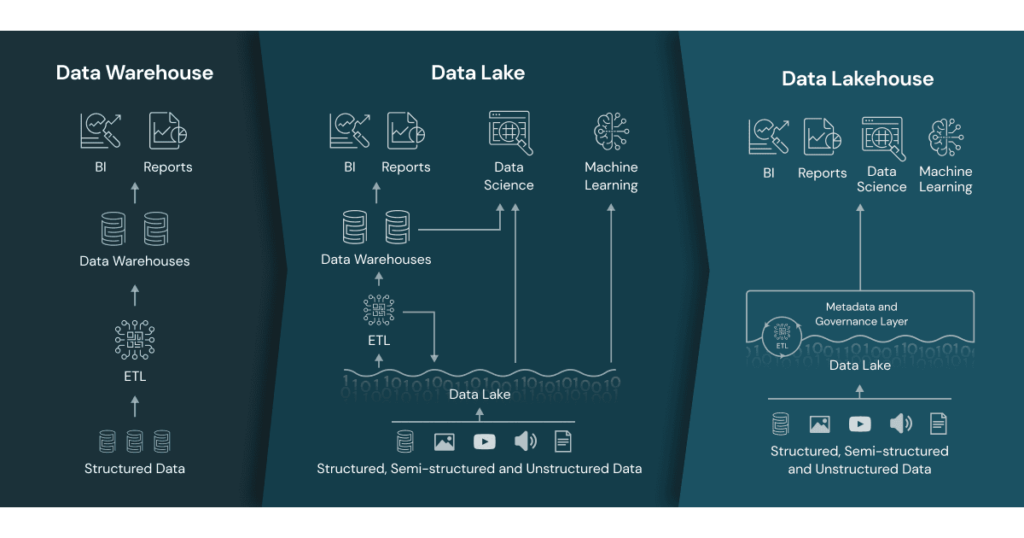
データウェアハウスとは?
データウェアハウス(Data Warehouse)は、データを保存、クエリ、および操作するためのリポジトリおよびプラットフォームです。特に、意思決定支援やビジネスインテリジェンス向けに最適化された構造化データの管理に適しています。
データウェアハウスの歴史と進化
データウェアハウスの概念は1970年代のデータマートに遡ります。1990年代初頭にIBMによって商業化され、データをサイロ化して管理するデータマートの非効率性を改善しました。
その後、Google BigQuery、Amazon Redshift、Microsoft Synapse、Snowflake、Teradataなど、多くのテクノロジー企業が発展を牽引してきました。最新のデータウェアハウスは、超並列処理(MPP)や分散コンピューティング技術の活用により、かつてのシステムよりも柔軟性と拡張性が向上しています。
データウェアハウスの特徴
- データの厳格な構造化:独自のデータ形式とスキーマが適用され、厳格なガバナンスが確保される。
- エンドユーザー向けの使いやすさ:データレイクに比べて学習コストが低く、技術知識が少ないユーザーでも扱いやすい。
- 柔軟性の制限:データウェアハウスは、データの一貫性を保つ代わりに、柔軟性や透明性が制限される。
- クラウド化の進展:モバイルデバイスやクラウドコンピューティングの普及により、従来型のデータウェアハウスからクラウドデータウェアハウスへの移行が進んでいる。
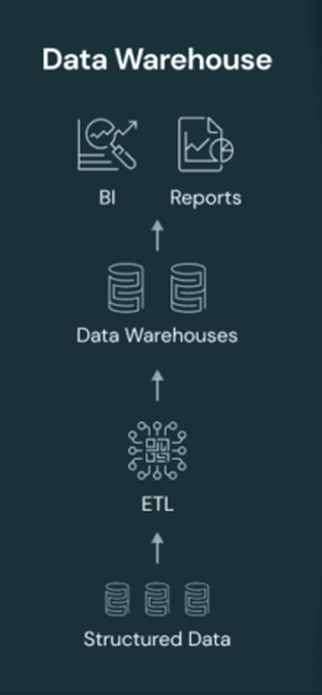
データレイクとは?
データレイク(Data Lake)は、データサイエンスやディープラーニング向けに、より柔軟なデータ管理を実現するプラットフォームです。データウェアハウスが主に構造化データを扱うのに対し、データレイクは非構造化データや半構造化データをサポートします。
データレイクの特徴
- オープンソース技術の活用:Apache HudiやDelta Lakeなどの技術を活用し、主要なクラウドサービス(Google BigLake、Azure Data Lake、AWS S3 Data Lakes)と統合可能。
- 柔軟なデータ格納:ETL(抽出・変換・ロード)なしで生データを格納し、必要に応じて処理を適用。
- コスト効率の最適化:クラウドプロバイダーのスポットインスタンスを利用することで、コスト削減が可能。
- データ管理の難しさ:適切に最適化されていない場合、データの増大による管理コストが高くなる可能性も。
NetflixやUberなどの企業では、データレイクとデータウェアハウスを組み合わせたハイブリッドアプローチを採用し、データ活用の最適化を図っています。
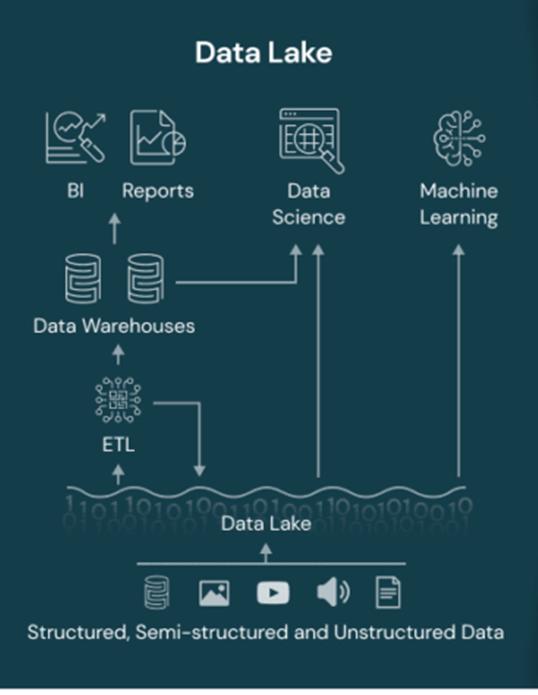
データレイクハウスとは?
データレイクハウス(Data Lakehouse)は、データウェアハウスとデータレイクの利点を統合した新しいアーキテクチャです。
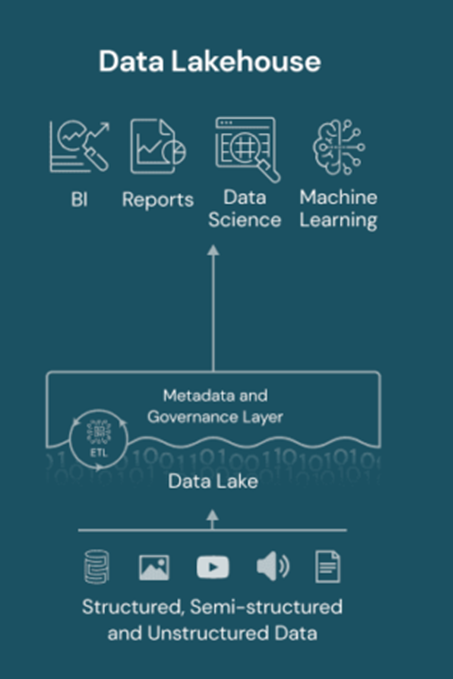
また、レイクハウスは Python や R とより自然に連携し、構造化データを最新の状態に保つための継続的な ETL とスキーマをサポートし、ビジネス インテリジェンス ダッシュボードや SQL などの言語を使用したリレーショナル クエリを可能にします。最後に、レイクハウスで使用されるオープンデータ形式により、ベンダーロックインのリスクが軽減されます。
データ レイクとは対照的に、レイクハウスは ACID (アトミック性、一貫性、独立性、耐久性) トランザクションをサポートしているため、複数のユーザーが同時にデータにアクセスして分析することによる副作用を回避できます。
データレイクハウスの特徴
- データウェアハウスの信頼性とデータレイクの柔軟性を統合
- メタデータとインデックスの追加によるデータ管理の向上
- ACIDトランザクションのサポートにより、データの一貫性を確保
- オープンデータフォーマットの採用でベンダーロックインを回避
- PythonやRとの連携を強化し、機械学習やデータサイエンス向けに最適化
Databricksがレイクハウスのコンセプトを推進し、2020年にホワイトペーパーでその詳細を紹介しました。
データウェアハウス、データレイク、データレイクハウスの比較
| データウェアハウス | データレイク | データレイクハウス | |
|---|---|---|---|
| データタイプ | 構造化データのみ | 構造化・半構造化・非構造化データ | 構造化・半構造化・非構造化データ |
| 基盤 | 独自技術 | オープンソース | オープンソース |
| 学習曲線 | 浅い(SQLベース) | 急峻(プログラミングスキル必須) | 中程度(SQL+プログラミング) |
| ガバナンス | 厳格なスキーマ、ACIDトランザクション | ほぼなし | ACIDトランザクション、メタデータ管理 |
| 理想的な用途 | ビジネスインテリジェンス、リレーショナル分析 | データサイエンス、機械学習 | BI、ML、データサイエンス |
- データウェアハウスは構造化データを扱うビジネス分析に適している。
- データレイクは柔軟性が高く、データサイエンスや機械学習向け。
- データレイクハウスは、両者の長所を融合した最新の選択肢。