【データ分析】ETLとELTの違い
データ処理の手法には ETL(Extract, Transform, Load) と ELT(Extract, Load, Transform) があります。それぞれの違いを詳しく見ていきます。
目次
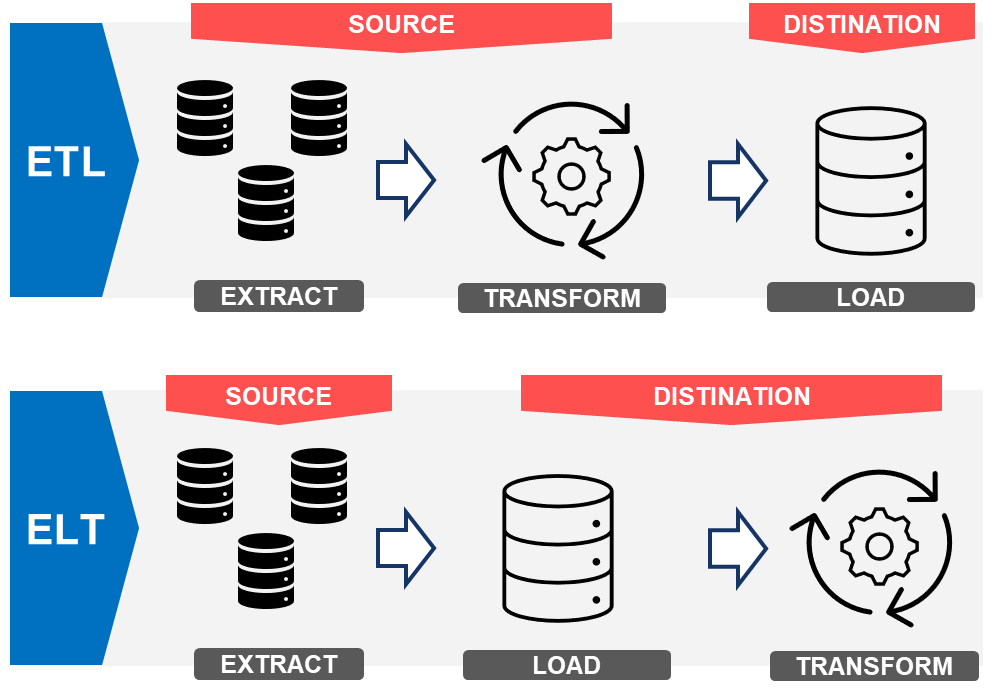
ETLとELTの主な違い
| 項目 | ETL | ELT |
|---|---|---|
| 処理順序 | 抽出 → 変換 → ロード | 抽出 → ロード → 変換 |
| データ変換の場所 | データウェアハウスにロードする前に変換 | データウェアハウス内で変換 |
| データの即時性 | 変換後にロードするため、データの即時性が低い | ロード後に変換するため、データの即時性が高い |
| データ品質 | 事前に変換するため、高いデータ品質を確保 | 後で変換するため、データガバナンスが必要 |
| スケーラビリティ | 大量のデータ処理には限界がある | 大量のデータ処理に適している |
| 柔軟性 | 変換が事前定義されており、柔軟性が低い | 変換がオンデマンドで行われ、柔軟性が高い |
| コスト | 複雑なETLプロセスや大規模データセットではコストが高くなる可能性がある | 特にクラウドベースのソリューションでは、コスト効率が高い可能性がある |
| 適用例 | 高いデータ品質や事前定義された分析ニーズが求められる場合に適している | 大量データ、リアルタイム分析、アジャイルなデータ探索に適している |
| 適用環境 | オンプレミス、従来型DWH | クラウドDWH、データレイク |
| スキーマの適用 | スキーマ・オン・ライト(※1) | スキーマ・オン・リード(※2) |
| データ分析 | 事前に整理されたデータを利用 | 柔軟な分析が可能 |
| 用途 | BIレポート、バッチ処理 | 機械学習、リアルタイム分析 |
※(1) スキーマ・オン・ライト: データを書き込む前にスキーマを定義し、整合性を確保する方式
※(2) スキーマ・オン・リード: データを保存する際のスキーマを固定せず、読み取るときに必要な形式に変換する方式
ETL(Extract, Transform, Load)とは?
概要
ETLは、データを
抽出(Extract)→ 変換(Transform)→ 格納(Load)
の順で処理する方式です。主にデータウェアハウス(DWH)向けに用いられ、データを事前に整形してから保存するのが特徴です。この手法は、データがターゲットシステムにロードされる前に変換されるため、データ品質が高く、事前に定義された分析ニーズに適しています。
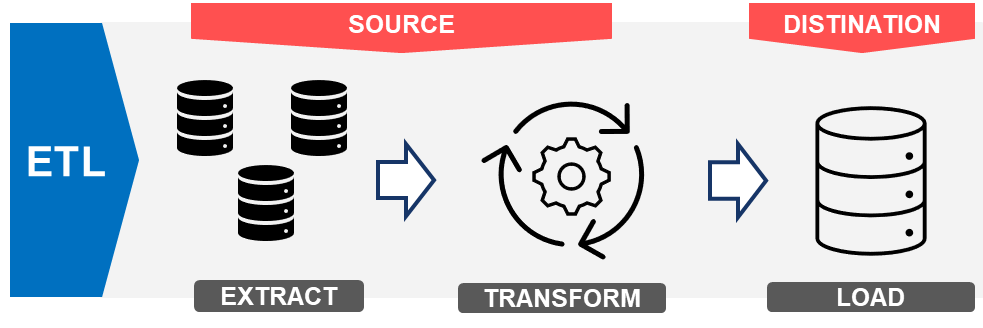
処理の流れ
- Extract(抽出)
- データを様々なソース(データベース、API、ログ、CSVなど)から取得
- Transform(変換)
- データをクリーニング(欠損値処理、異常値処理)
- 正規化、結合、集約
- スキーマ変換(異なるデータフォーマットを統一)
- Load(格納)
- 変換済みデータをDWHにロード
特徴
- データ変換をDWHに保存する前に行う
- 高品質なデータを提供(一貫性が確保される)
- 処理負荷が高い(変換処理を行うため)
- バッチ処理が中心(定期的にデータを更新)
- レガシーDWHやオンプレミス環境でよく使われる
適したユースケース
- BI(ビジネスインテリジェンス)レポート作成
- DWHでのデータ分析
- 事前にクリーンなデータを提供する必要がある場合
代表的なツール
- Talend
- Apache Nifi
- AWS Glue
- Microsoft SSIS(SQL Server Integration Services)
ELT(Extract, Load, Transform)とは?
概要
ELTは、データを
抽出(Extract)→ 格納(Load)→ 変換(Transform)
の順で処理する方式です。ETLとは異なり、データの変換をDWHやデータレイクの内部で行うのが特徴です。この手法は、大量のデータやリアルタイム分析、柔軟なデータ探索に適しており、変換がターゲットシステム内でオンデマンドで行われます。
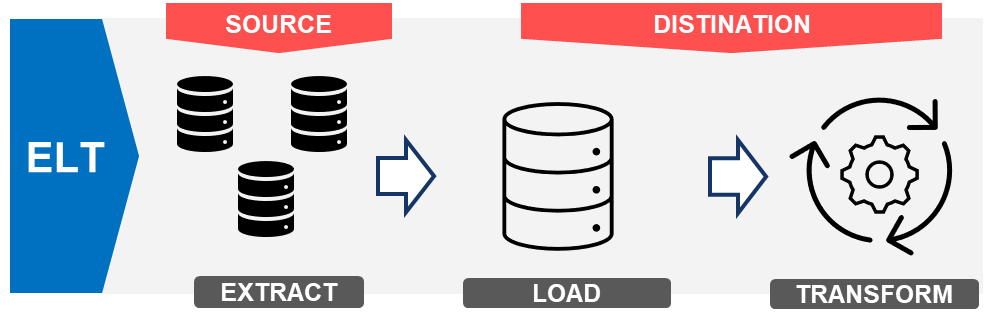
処理の流れ
- Extract(抽出)
- データを様々なソース(データベース、API、ログ、CSVなど)から取得
- Load(格納)
- 生データのままデータウェアハウスやデータレイクにロード
- Transform(変換)
- 必要なタイミングでデータを変換(SQLクエリやワークフローを使用)
特徴
- データ変換をDWHやデータレイク内で行う
- データの保存が高速(変換を後回しにできる)
- クラウド環境向けに最適化(スケーラブルなリソースを活用)
- ストリーミング処理にも対応しやすい
- スキーマ・オン・リード(Schema-on-Read)
- 必要な時にスキーマを適用し、異なるデータフォーマットを柔軟に処理できる
適したユースケース
- データレイクでの機械学習・データ探索
- クエリの柔軟性が求められるDWH(BigQuery, Snowflake, Redshiftなど)
- リアルタイム処理やストリーミングデータの分析
代表的なツール
- Google BigQuery
- Snowflake
- Amazon Redshift Spectrum
- Databricks
- Azure Synapse Analytics
ETLとELTの利点と欠点
ETLの利点
- 高速な分析: データが事前に変換・構造化されているため、クエリの実行が効率的であり、迅速な分析が可能です。
- 環境の柔軟性: オンプレミスやクラウド環境の両方で実装可能であり、既存のシステムとの統合が容易です。
- コンプライアンス: データがターゲットシステムにロードされる前に変換されるため、GDPRやHIPAAなどのデータプライバシー規制に対応しやすく、機密データのマスキングや暗号化が可能です。
- 成熟度: ETLは20年以上の歴史があり、豊富なツールや専門家が存在します。
ETLの欠点
- ロード速度: データの変換が事前に行われるため、データのロードに時間がかかる場合があります。
- ワークフローの硬直性: データウェアハウスのスキーマや変換プロセスが固定されているため、新たな分析ニーズに対応する際に柔軟性が欠けることがあります。
- データ量の制限: 大量のデータ処理には時間がかかるため、小規模なデータセットに適しています。
ELTの利点
- データ形式の柔軟性: データレイクを使用することで、構造化・非構造化を問わず、あらゆる形式のデータを取り込むことができます。
- オンデマンドの変換: 分析が必要なときにデータを変換するため、リソースの効率的な利用が可能です。
- 高いデータ可用性: すべてのデータがデータレイクにロードされるため、常にデータが利用可能であり、即時のアクセスが可能です。
- ロード速度: データの変換が後で行われるため、データのロードが迅速に行われます。
- 実装の迅速性: 新しいデータソースに対しても、データをすぐにデータレイクに取り込むことができ、エンジニアが最適なクエリや分析方法を検討する時間を確保できます。
ELTの欠点
- コンプライアンス: 変換前のデータがそのまま保存されるため、機密データの保護や規制遵守のために、追加のデータガバナンスやセキュリティ対策が必要です。
- 新しいアプローチ: ELTは比較的新しいデータ処理アプローチであり、ETLに比べてツールやベストプラクティスが成熟していません。そのため、適切なデータ管理やガバナンスの確立が必要です。
- クエリパフォーマンス: データの変換がデータウェアハウスやデータレイク内で行われるため、適切なリソース管理がされていないとクエリの実行速度が遅くなる可能性があります。
- スキルセットの要求: ELTを活用するには、SQLやデータエンジニアリングの知識が必要となるため、組織内でのトレーニングや専門家の確保が求められることがあります。
ETLとELTの適用例
ETLとELTは、それぞれ異なるユースケースに適しています。以下は、一般的な適用例をまとめたものです。
ETLが適しているケース
- 規制が厳しい業界(金融・医療など): データが事前に処理されるため、GDPRやHIPAAなどの規制に準拠しやすくなります。
- データ品質を重視する場合: 事前にデータがクレンジング・正規化されるため、一貫性のあるデータを提供できます。
- 従来型のデータウェアハウスを使用する場合: 既存のオンプレミス型データウェアハウス(例:Oracle、SQL Server)と統合するのに適しています。
- 定型的なBIレポートが主な用途の場合: 定期的なレポートやダッシュボード作成に適しており、事前にデータを整理することで分析を高速化できます。
ELTが適しているケース
- クラウド環境での大規模データ処理: クラウドベースのデータウェアハウス(例:BigQuery、Snowflake、Redshift)を利用する場合、スケーラビリティとコスト効率が向上します。
- リアルタイム分析やデータストリーミング: すばやくデータをロードできるため、リアルタイムのデータ処理に適しています(例:IoTデータ、ソーシャルメディア分析)。
- 非構造化データやマルチソースデータの統合: 構造化・非構造化を問わず多様なデータソースを統合し、必要に応じて変換できます。
- 機械学習・データサイエンス: 生データをそのまま保存できるため、柔軟なデータ探索や高度な分析が可能になります。
ETLとELTの選択基準
ETLとELTのどちらを採用すべきかは、以下の要因によって決まります。
| 評価基準 | ETL | ELT |
|---|---|---|
| データサイズ | 中小規模のデータに適している | 大規模データセットに最適 |
| 処理速度 | 事前変換が必要なため、リアルタイム性は低い | データの即時利用が可能でリアルタイム処理に適している |
| データ品質 | 高品質なデータを提供 | データ品質管理はユーザーの責任 |
| コスト | 事前処理にコストがかかる | クラウド環境ではコスト効率が高い |
| コンプライアンス | 厳格な規制がある場合に適している | データガバナンスの設計が必要 |
| 柔軟性 | 事前に定義されたデータモデルに基づく | 分析の自由度が高い |
✅ ETLが適しているケース
- 事前にデータを整形し、高品質なデータを提供する必要がある
- 従来型DWH(オンプレミス、SQL Server, Oracleなど) を使用している
- 厳格なデータ管理・ガバナンス が必要な場合
- バッチ処理がメイン の環境
✅ ELTが適しているケース
- クラウドDWH(BigQuery, Snowflake, Redshift) を利用
- データレイク に大量のデータを格納して分析
- データサイエンスや機械学習 に活用
- リアルタイムデータ処理(ストリーミング)を行う
まとめ
ETLとELTは、それぞれ異なる特性と利点を持つデータ処理手法です。
- ETLは、データ品質を重視し、規制が厳しい業界や従来型のデータウェアハウス環境での利用に適しています。
- ELTは、クラウド環境、大規模データ、リアルタイム分析の用途に適しており、柔軟なデータ活用が可能です。