【AI開発者必見】実運用で使えるRAGアーキテクチャ9選!失敗しない選び方と実装ガイド
- 1. はじめに:RAGの重要性
- 2. 本番環境で役立つ9つのRAGアーキテクチャ
- 2.1. 1. 標準RAG:基本構成
- 2.2. 2. 会話型RAG (Conversational RAG):文脈の保持
- 2.3. 3. 修正型RAG (Corrective RAG, CRAG):品質の自己検査
- 2.4. 4. 適応型RAG (Adaptive RAG):難易度別のルーティング
- 2.5. 5. 自己RAG (Self-RAG):AIによる自己評価
- 2.6. 6. 融合型RAG (Fusion RAG):多角的な検索拡張
- 2.7. 7. HyDE (Hypothetical Document Embeddings):架空の回答からの逆引き検索
- 2.8. 8. エージェント型RAG (Agentic RAG):自律的な調査の実行
- 2.9. 9. グラフRAG (GraphRAG):関係性の推論
- 3. RAGアーキテクチャの選定ステップ
- 4. まとめ
はじめに:RAGの重要性
自社のチャットボットが、顧客に対して「返品期間は90日です(実際は30日)」と誤った案内をしたり、存在しない機能をでっち上げて説明してしまうケースがあります。
これは、デモ環境と本番(プロダクション)システムの間に存在する決定的なギャップです。
大規模言語モデル(LLM)は、事実と異なる情報でも確信に満ちた文章で出力する「ハルシネーション」を起こしやすいため、そのまま本番環境へ投入すると企業の信用問題やコスト増大を招きます。
AIモデルを事実に基づいた正確な情報で動かすためには、RAG(Retrieval-Augmented Generation:検索拡張生成)の導入が不可欠です。
ただし、「これさえ導入すればよい」という万能なRAGは存在しません。
解決したいビジネス課題や扱うデータによって最適なアーキテクチャは異なり、初期設計を誤ると大きな手戻りが発生します。
本記事では、本番環境で確実に機能する「9つのRAGアーキテクチャ」について、具体的なユースケースを交えて解説します。
RAGの基本プロセスと導入メリット
RAGとは、LLMが回答を生成する前に、外部の信頼できるデータベース(ナレッジベース)を参照させることで、出力品質をコントロールする技術です。
AIの事前学習データに頼るのではなく、自社独自の社内規定、顧客データ、最新のWeb記事などから関連情報を抽出し、それを元に回答を生成させます。
具体的な処理の流れは以下の通りです。
- 1. 検索・抽出: ユーザーの質問を受け取り、外部ソースから関連情報を検索・抽出します。
- 2. コンテキストの結合: 抽出した情報をユーザーの質問文と組み合わせ、LLMへ渡すプロンプト(コンテキスト)を作成します。
- 3. 回答の生成: 渡された「検証可能な事実」に基づいて、LLMが回答を生成します。
これによりハルシネーションを大幅に抑え込み、情報の出どころが明確な信頼性の高いシステムを構築できます。
graph TD
A[ユーザーの質問] --> B{関連情報の検索・取得}
B --> C[検索結果 : コンテキスト]
C --> D[LLMへコンテキストと質問を送信]
D --> E[LLMからの回答生成]
E --> F[ユーザーへ回答]
【補足】RAG設計の重要パラメータ
各アーキテクチャの解説に入る前に、RAGの精度を左右する基本パラメータを確認しておきます。
- Chunk Size(チャンクサイズ): ドキュメントを分割する際の文字数やトークン数。大きすぎるとノイズが混ざり、小さすぎると文脈が途切れます。
- Chunk Overlap(チャンクオーバーラップ): 分割したチャンク同士の重複部分。文章の前後関係が途切れるのを防ぎます。
- Top-K: ベクトル検索で取得する上位ドキュメントの数。増やすと網羅性は上がりますが、APIコストや処理速度が悪化します。
- Distance Metric(距離指標): コサイン類似度やユークリッド距離など、文章同士の意味の近さを計算する基準です。
本番環境で役立つ9つのRAGアーキテクチャ
本番環境で効果を発揮する9つのRAGアーキテクチャの仕組みと、それぞれのメリット・デメリットを解説します。
1. 標準RAG:基本構成
標準RAGは、最も基本となる構成です。
検索処理をシンプルな1回のルックアップで完結させます。手軽に自社データとAIを連携できる反面、検索エンジンが常に最適な結果を返すことを前提としています。
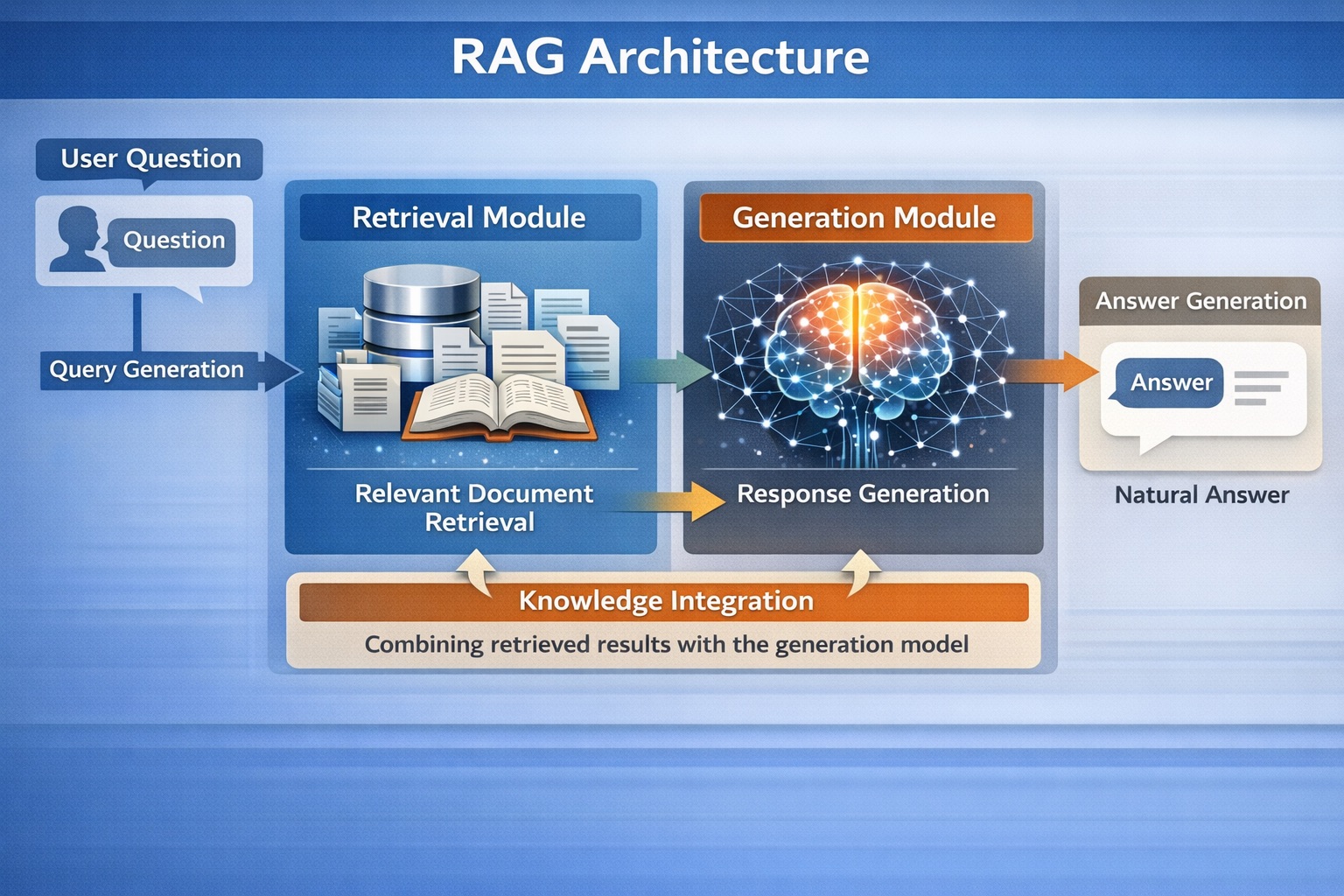
処理速度が最優先され、情報に多少の揺らぎがあっても問題になりにくい低リスクな用途に向いています。
- チャンキング: ドキュメントを扱いやすいテキストセグメントに分割します。
- エンベディング: 分割したテキストをベクトル化し、ベクトルデータベースに保存します。
- 検索: ユーザーの質問をベクトル化し、類似度の高いテキスト(Top-K)を取得します。
- 生成: 取得した情報をコンテキストとしてLLMに渡し、回答を生成させます。
【利用例】
社内規定の検索ボット。「経費精算の期限は?」という質問に対し、マニュアルの該当箇所を見つけて回答します。
- Pros: レスポンスが高速。計算コストが安く、保守・運用が容易。
- Cons: 質問と無関係なノイズを拾いやすい。複数の条件が絡む複雑な質問には対応不可。
2. 会話型RAG (Conversational RAG):文脈の保持
会話型RAGは、チャットボット特有の「文脈が途切れる」課題を解決します。
直前のやり取りを保持する記憶層(メモリ)を追加し、チャットのターンごとに文脈を補完します。
- コンテキストの読み込み: 直近の会話履歴(5~10往復分)を保持します。
- クエリの書き換え: 会話履歴を元に、指示語などを補完した明確な質問文にLLMが書き換えます。
- 検索と生成: 書き換えた質問文で検索を実行し、回答を生成します。
【利用例】
カスタマーサポートボット。「パスワードを忘れました」の後に「どこでリセットできますか?」と入力されても、システムは「パスワードのリセット手順」として的確に処理します。
- Pros: 自然な対話体験を提供できる。
- Cons: 過去の雑談がノイズになる「メモリドリフト」が発生しやすい。クエリ書き換え処理により遅延とAPIコストが増加する。
3. 修正型RAG (Corrective RAG, CRAG):品質の自己検査
CRAGは、情報の正確性が極めて重要な高リスク環境向けのアーキテクチャです。
取得したドキュメントの品質を判定する評価ゲート(グレーダー)を挟み、品質が低いと判断した場合は自動で外部のWeb検索などへフォールバックします。
graph TD
A[ユーザーの質問] --> B[内部データベースから検索]
B --> C{評価モデルによる品質チェック}
C -->|スコア: 合格| D[LLMで回答生成]
C -->|スコア: 不合格/グレー| E[外部APIやWeb検索へ切り替え]
E --> F[最新の外部情報を取得]
F --> D
【利用例】
金融アドバイザーAI。社内データベースにない最新の株価を聞かれた際、自ら情報不足を認識し、株価APIを叩いて最新情報を取得します。
- Pros: ハルシネーションの発生を大幅に抑制できる。社内データと最新の外部データを連携できる。
- Cons: 評価ステップが入るため応答遅延が生じる。外部APIの利用制限やコスト管理が必要。
4. 適応型RAG (Adaptive RAG):難易度別のルーティング
適応型RAGは、すべての質問に重い検索処理を回す無駄を省きます。
分類モデル(ルーター)を利用して質問の難易度を判定し、最適な処理ルートへ振り分けます。
- パスA (検索なし): 挨拶や、LLMが素の状態で答えられる一般常識。
- パスB (標準RAG): 営業時間やマニュアル確認などのシンプルな事実検索。
- パスC (マルチステップ): 複数の資料をまたいで分析する複雑な質問。
【利用例】
社内ヘルプデスク。「Wi-Fiパスワードは?」には標準RAGで即答し、「過去3年間のIT予算推移」には高度な分析モードで対応します。
- Pros: 簡単な質問へのリソース浪費を防ぎ、システム全体の大幅なコスト削減と高速化を実現。
- Cons: ルーティング精度が低いと、難しい質問を簡単だと誤認して不適切な回答を返すリスクがある。
5. 自己RAG (Self-RAG):AIによる自己評価
自己RAGは、LLM自身が生成中の文章をリアルタイムで批判・修正するアーキテクチャです。
「内容が質問の意図に合っているか」「参照ドキュメントに裏付けがあるか」を自己評価し、不足があれば生成を停止して再検索と修正を行います。
【利用例】
法務部門向けの判例リサーチ。AIが判例結果を書き出しながら、根拠となる情報が不足していることに気づくと、自動でデータベースを再検索して内容を修正します。
- Pros: 情報の裏付け(グラウンディング)が強固。確実な事実のみを出力させたい用途に最適。
- Cons: 専用に調整されたモデルが必要。処理の反復により計算コストと待ち時間が膨大になる。
6. 融合型RAG (Fusion RAG):多角的な検索拡張
融合型RAGは、ユーザーの検索スキルのばらつきを吸収します。
1つの質問から複数の言い換えバリエーションを自動生成し、多角的に並行検索を行うことで情報の取りこぼしを防ぎます。
- クエリ拡張: 質問文から3~5パターンの検索キーワードを作成します。
- 並列検索と再ランク付け: 全パターンで検索し、Reciprocal Rank Fusion (RRF) 等で結果をスコアリングして重要なドキュメントを抽出します。
【利用例】
医療文献検索。「不眠症の治し方」という入力に対し、「睡眠障害 薬物療法」「CBT-I」等の専門用語でも並行検索し、関連論文を網羅します。
- Pros: 検索の網羅性(想起率)が高い。ユーザーの入力が曖昧でも適切な資料を探し出せる。
- Cons: 検索回数が増加するためAPIコストがかさみ、再計算処理による遅延も発生する。
7. HyDE (Hypothetical Document Embeddings):架空の回答からの逆引き検索
HyDEは、短い質問文と詳細なマニュアル文との間にある「語彙のズレ」を解決します。
LLMにまず「架空の模範解答」を作らせ、その解答文と意味が似ている本物のドキュメントを探し出します。
- 仮説立て: 質問に対してLLMが偽の解答を生成します。
- 検索と生成: 偽の解答をベクトル化して検索し、ヒットした本物のドキュメントを使って正確な回答を再生成します。
【利用例】
「カリフォルニアのデジタルプライバシー法とは?」という漠然とした質問に対し、AIがCCPAの架空の要約文を作成し、それを手がかりに実際の条文を検索します。
- Pros: 抽象的な質問に対する検索ヒット率が劇的に向上する。
- Cons: 初期の「架空の解答」が的外れな場合、無関係なドキュメントばかりを集めるリスクがある。
8. エージェント型RAG (Agentic RAG):自律的な調査の実行
エージェント型RAGは、LLMに自律的なリサーチャーとしての権限を与え、情報収集の手順計画から回答作成までを実行させるオーケストレーション手法です。
graph TD
A[ユーザーの質問] --> B{AIが意図を分析し、調査計画を立案}
B --> C{ツールを実行 : DB検索, Web検索, 計算}
C --> D{取得情報の検証と不足の確認}
D -- 不足があれば再調査 --> C
D --> E[証拠がすべて揃う]
E --> F[最終的な回答の生成]
【利用例】
「インドの法規制上、ローン審査にAIを使っても問題ないか?」という複雑な質問に対し、「関連ガイドラインのWeb検索」→「社内規程の検索」→「情報の突き合わせ」という手順をAI自らが踏んで見解をまとめます。
- Pros: 複数の条件が絡む複雑な調査依頼に対応できる。
- Cons: 処理ステップが多いため非常に時間がかかり、運用コストも高額。単純な検索にはオーバースペック。
9. グラフRAG (GraphRAG):関係性の推論
グラフRAGは、文章の意味的な類似度ではなく、「人物や組織などのエンティティ」と「その関係性」をナレッジグラフ(ネットワーク図)として構築し、検索する手法です。
「Aという出来事がBにどう影響したか」という論理的なつながりを追跡します。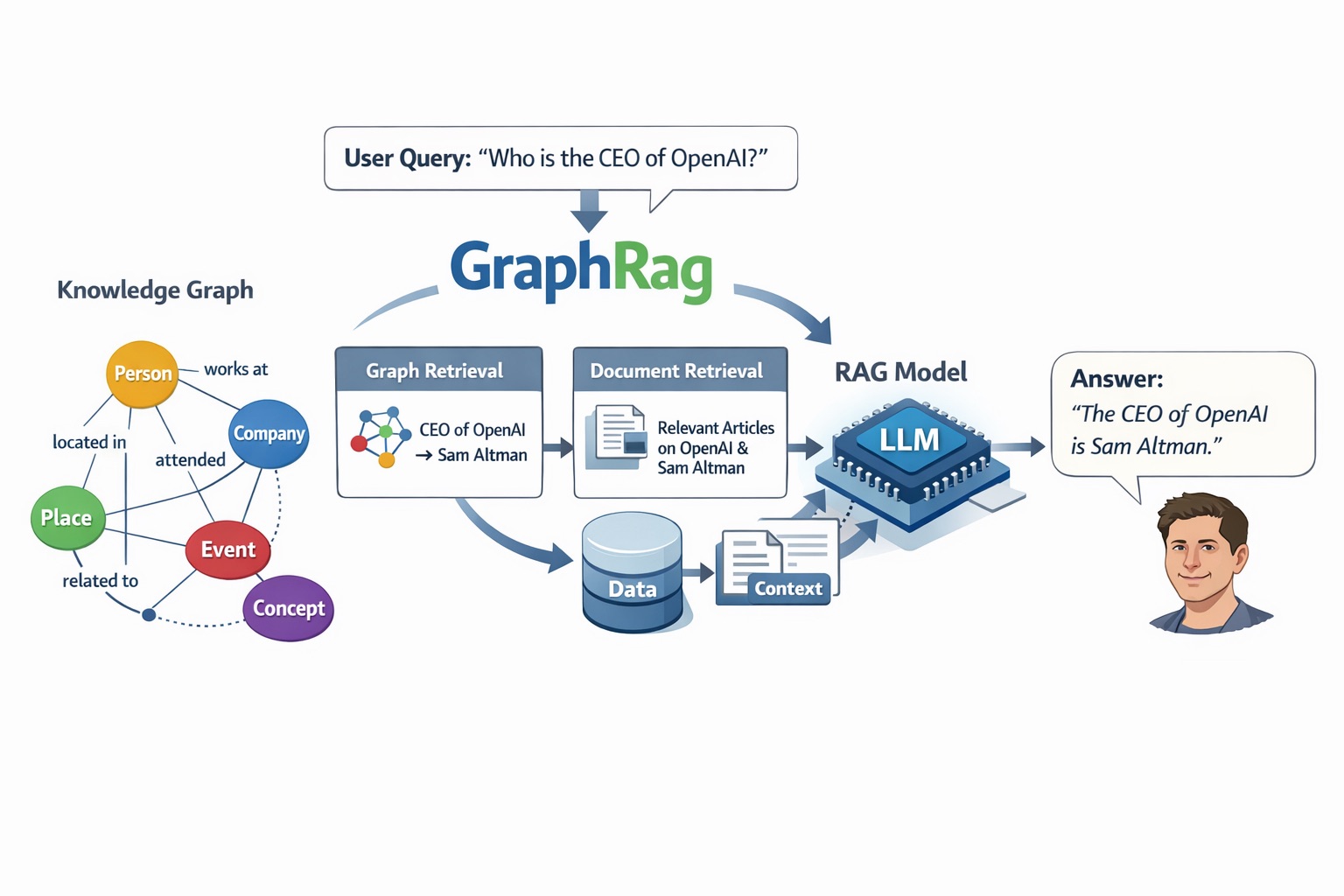
【利用例】
「金利決定はスタートアップの企業価値にどう影響するか?」という質問に対し、「金利上昇 → VCの資金調達環境の悪化 → アーリーステージの企業価値低下」という因果関係をグラフから辿って回答します。
- Pros: 因果関係やルールに基づく推論に強く、回答の根拠が極めて明確。タスクによっては99%近い高精度を実現する。
- Cons: ナレッジグラフの構築と維持に莫大な初期投資とデータ整理の労力が必要。
RAGアーキテクチャの選定ステップ
自社のプロジェクトに最適なアーキテクチャを選定するためのステップは以下の通りです。
ステップ1: まずは「標準RAG」から着手する
明確な理由がない限り、基本構成である標準RAGから始めます。
チャンキングの最適化や評価指標の確立といった基礎を固めずに複雑な仕組みを導入しても、運用は破綻します。
ステップ2: 実際の「ユーザーの質問ログ」に合わせて拡張する
想定ではなく、実際にユーザーが入力するクエリの傾向を見て判断します。
- 指示語を含む追加質問が多い: 会話型RAGを追加する。
- 単純な質問と複雑な調査が混在する: 適応型RAGを導入し、コストを最適化する。
- 表記揺れが多く検索ヒット率が低い: 融合型RAGやHyDEで網羅性を高める。
- 回答ミスが大きな損失に直結する: 修正型RAGや自己RAGを導入し、ハルシネーションをブロックする。
ステップ3: 複数の仕組みを組み合わせる(ハイブリッド構築)
実運用では複数のアプローチを組み合わせます。
「基本は標準RAGで高速処理し、検索スコアが低い場合のみ修正型RAGでWeb検索にフォールバックする」といった設計にすれば、全体の95%はスピーディに処理し、残りの5%のイレギュラーにも安全に対応できます。
まとめ
RAGは万能ではありません。参照元のドキュメントが整理されておらず、検索精度自体が低ければ、どれほど高度なアーキテクチャを採用しても不正確な回答を出力します。
自社の課題に合ったアーキテクチャを適切に設計・実装することで初めて、LLMは信頼できる業務システムとして機能します。
RAGプロジェクトを成功させるための鉄則は以下の3点です。
- 過剰な設計(Over-Engineering)を避ける: 単純な社内FAQボットにエージェント型RAGを導入するなど、要件に見合わないオーバースペックな設計は避けます。
- 検索品質を最優先する: 品質の低い検索結果からは質の低い回答しか生まれません。RAGの成否は検索(Retrieval)の精度に大きく依存します。
- 効果測定を継続する: 回答精度、レスポンス速度、APIコストをモニタリングし、数値に基づく改善サイクルを回します。
最適なシステムとは、限られた予算と要件の中で、ユーザーが求める正確な回答を迅速に提供できるシステムです。まずはシンプルに小さく始め、計測結果に基づいて必要な拡張を行ってください。