MLOps入門:#1 データサイエンスのワークフローを理解しよう
目次
はじめに
MLOps(エムエルオプス)とは、機械学習とDevOpsを融合させた分野になります。
要するに、機械学習の開発から運用までをスムーズに自動化して、もっと効率的にしようという考え方です。
この記事では、データが実験段階から運用に移る流れをざっくりと説明していきます。
データサイエンスのパイプラインとワークフローをざっくり紹介
データサイエンスのパイプラインは、データをどうやって使える形にするかを段階ごとにまとめた流れです。
それぞれのステップが次のステップの土台となり、最終的に本番環境で使えるモデルが完成するイメージです。
この流れは一度で終わりじゃなく、何度も繰り返し行われるのが特徴です。データやモデルの品質は、定期的な見直しや更新が必要になります。
データサイエンスワークフローのステージを一つずつ解説
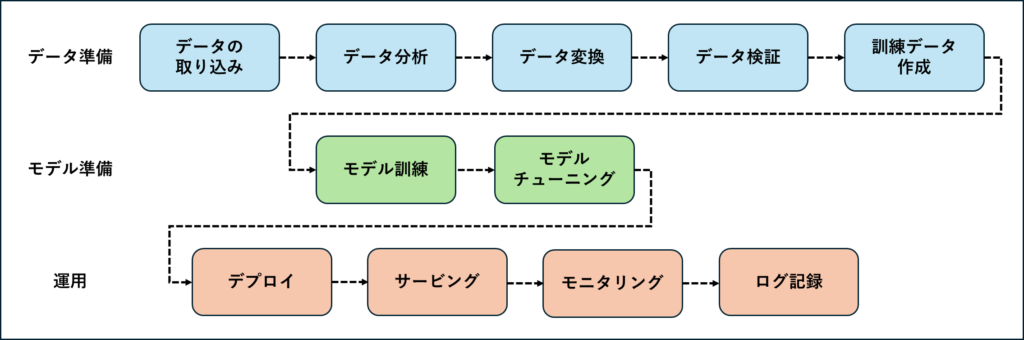
- データ準備
- データの取り込み: データベースやAPI、クラウドなどから必要なデータを集めてきます。
- データ分析: データの中身をざっと確認して、どんな構造や問題があるかを見ます。
- データ変換: モデリングに使えるようにデータをクリーンアップして、使いやすい形に整えます。
- データ検証: 欠損値や異常値がないかを確認して、データの品質をチェックします。
- 訓練データ作成: モデルを訓練、テスト、評価するためにデータを分割します。
- モデル準備
- モデル訓練: 訓練データを使って、アルゴリズムを元にモデルを学習させます。
- モデルチューニング: ハイパーパラメータを調整して、モデルの精度をさらに引き上げます。
- 運用
- デプロイ: 学習済みのモデルを実際の運用環境に配置します。
- サービス化: モデルをAPIなどで利用できるようにセットアップします。
- モニタリング: モデルのパフォーマンスやデータの変化を定期的にチェックします。
- ログ記録: 結果やエラーを記録して、トラブルが発生したときに備えます。
MLOpsで目指す「自動化されたパイプライン」のゴール
MLOpsの目的は、これらのステージをすべて自動化し、機械学習の継続的インテグレーションとデリバリー(CI/CD)を実現することです。
自動化を支援するワークフローオーケストレーションツールやクラウドサービスについても触れます。最後に、自動化により迅速なイテレーション、スケーラビリティの向上、および本番環境での機械学習の効率的な管理が可能になります。
最後に
こちらの記事ではMLOpsの全体イメージについて解説しました。
今後は2章で紹介したデータサイエンスワークフローをデータの取り込みから一つずつ順番に解説していきたいと思います。
おすすめの書籍
リンク