MLOps入門:#3 データを分析してみよう
前回の記事はこちら
はじめに
今回は取り込んだデータの中身を見ていきます。
データ分析は、データサイエンスプロジェクトの出発点であり、MLOpsパイプラインの質を左右する重要なステップです。
データの構造や特徴を理解し、潜在的な問題や傾向を見つけることで、後続のモデル構築やチューニングがスムーズになります。
データ分析の重要性
モデルの性能は、データの質に大きく依存します。データの内容や傾向、欠損値などの問題点を理解しておくことが、効果的なモデリングの基盤となります。
データ分析によって得られる知見は、特徴量エンジニアリングやアルゴリズムの選定にも役立ちます。
データ分析のステップ
実際にダミーデータを使って分析をしてみます。
今回使用するデータは店舗の商品売り上げデータです。
1. データの概要確認
データはdataという変数で定義しています。
- データの形状(行数・列数)、カラム情報、中身を確認し、データセットの基本構造を把握します。
# データの形状
data.shape
# カラム情報
data.info()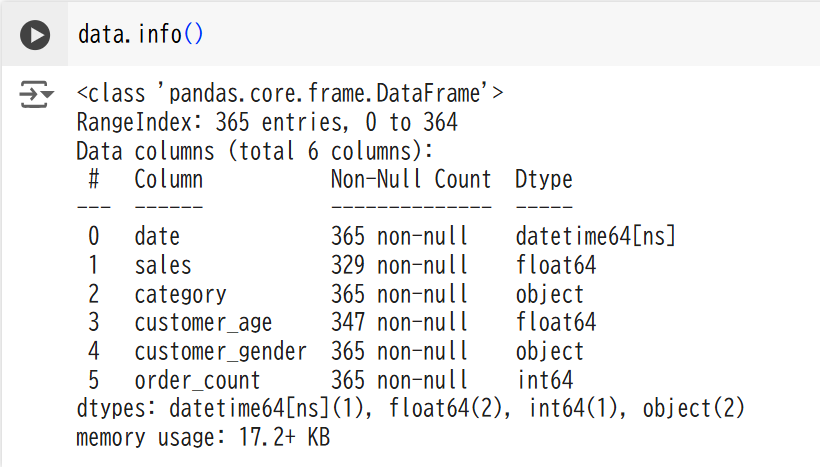
# データの中身
data.head() 
2. 基本統計量の確認
- 平均値、中央値、標準偏差、最小値、最大値といった統計量を確認することで、データの分布や範囲を理解します。
# 基本統計量の表示
print(data.describe())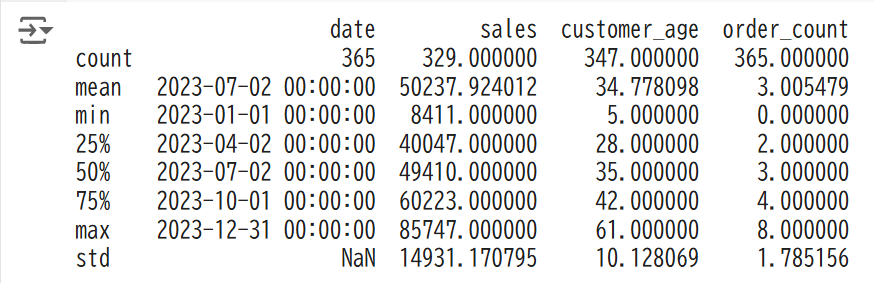
3. 欠損値の確認と処理
- 欠損値がどこに存在するかを確認し、欠損値が多い場合はドロップ、少ない場合は補完などの対応を考えます。
# 欠損値の確認
missing_data = data.isnull().sum()
print("欠損値の数:\n", missing_data)
# salesとcustomer_ageは平均値で補完
# categoryとcustomer_genderは最頻値で補完
data.fillna({
'sales': data['sales'].mean(),
'customer_age': data['customer_age'].mean(),
'category': data['category'].mode()[0],
'customer_gender': data['customer_gender'].mode()[0]
}, inplace=True)

今回のデータにはsalesカラムには36個、customer_ageカラムには18個の欠損値がありました。
salesとcustomer_ageは平均値で補完する処理をいれて欠損値は0になりました。
4. データの分布確認
- 数値データのヒストグラムを作成して、データがどのように分布しているかを確認します。
import matplotlib.pyplot as plt
# 数値データのヒストグラム
data.hist(bins=20, figsize=(15, 10))
plt.show()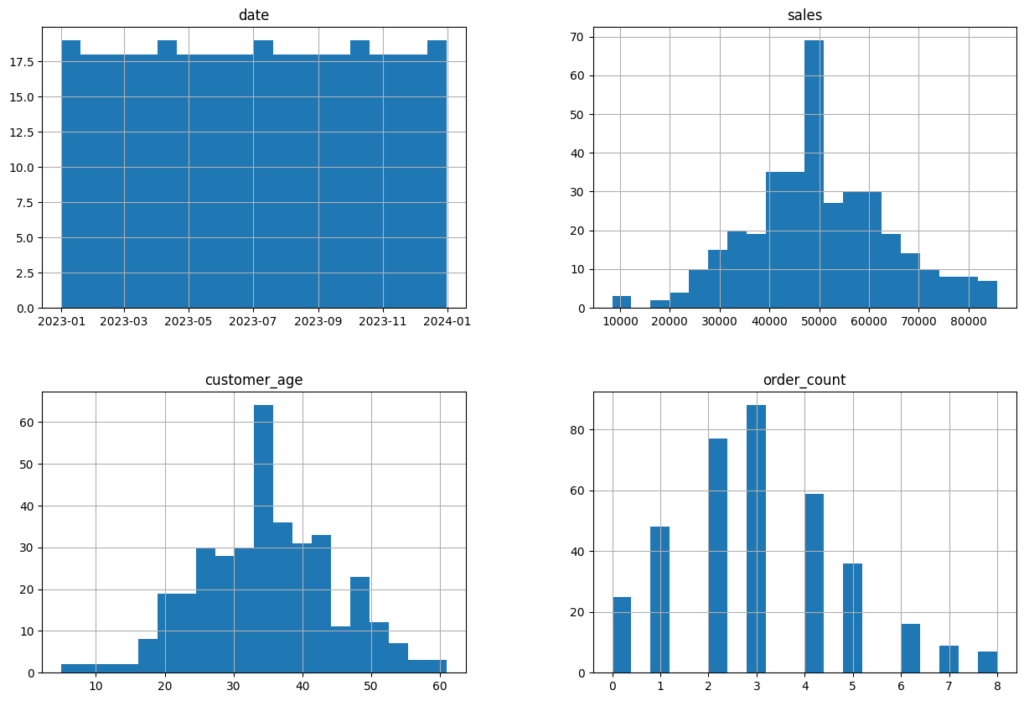
売上や顧客の年齢は正規分布に近い形になっています。
5. カテゴリ変数の確認
- カテゴリ変数のユニークな値を確認し、どのようにエンコードするかを検討します。
# カテゴリ変数のユニーク値
for col in data.select_dtypes(include="object").columns:
print(f"{col} のユニーク値: {data[col].unique()}")
データの相関分析
- 数値変数間の相関を確認し、相関の高い変数や特徴量エンジニアリングに役立つ変数を特定します。
import seaborn as sns
import matplotlib.pyplot as plt
# 数値カラムのみを抽出
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# 相関行列の計算
correlation_matrix = numeric_data.corr()
# 相関行列の表示
print("相関行列:\n", correlation_matrix)
# ヒートマップで可視化
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, cmap="coolwarm", square=True)
plt.title("相関行列のヒートマップ")
plt.show()
相関係数は1に近いほど相関が強いので今回のデータはカラム同士にはあまり相関がないことが分かります。
4. データの異常検知
- 外れ値(異常値)の検出は、データ分析の重要なステップの一つです。箱ひげ図や標準偏差を用いて異常値を特定します。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 数値カラムの取得
numeric_columns = data.select_dtypes(include=np.number).columns
# 各カラムをサブプロットで表示
num_cols = len(numeric_columns)
plt.figure(figsize=(12, 4 * num_cols))
for i, col in enumerate(numeric_columns, 1):
plt.subplot(num_cols, 1, i) # 縦に1列、カラム数分の行を持つサブプロット
sns.boxplot(data=data, x=col)
plt.title(f"{col} の箱ひげ図")
plt.tight_layout()
plt.show()
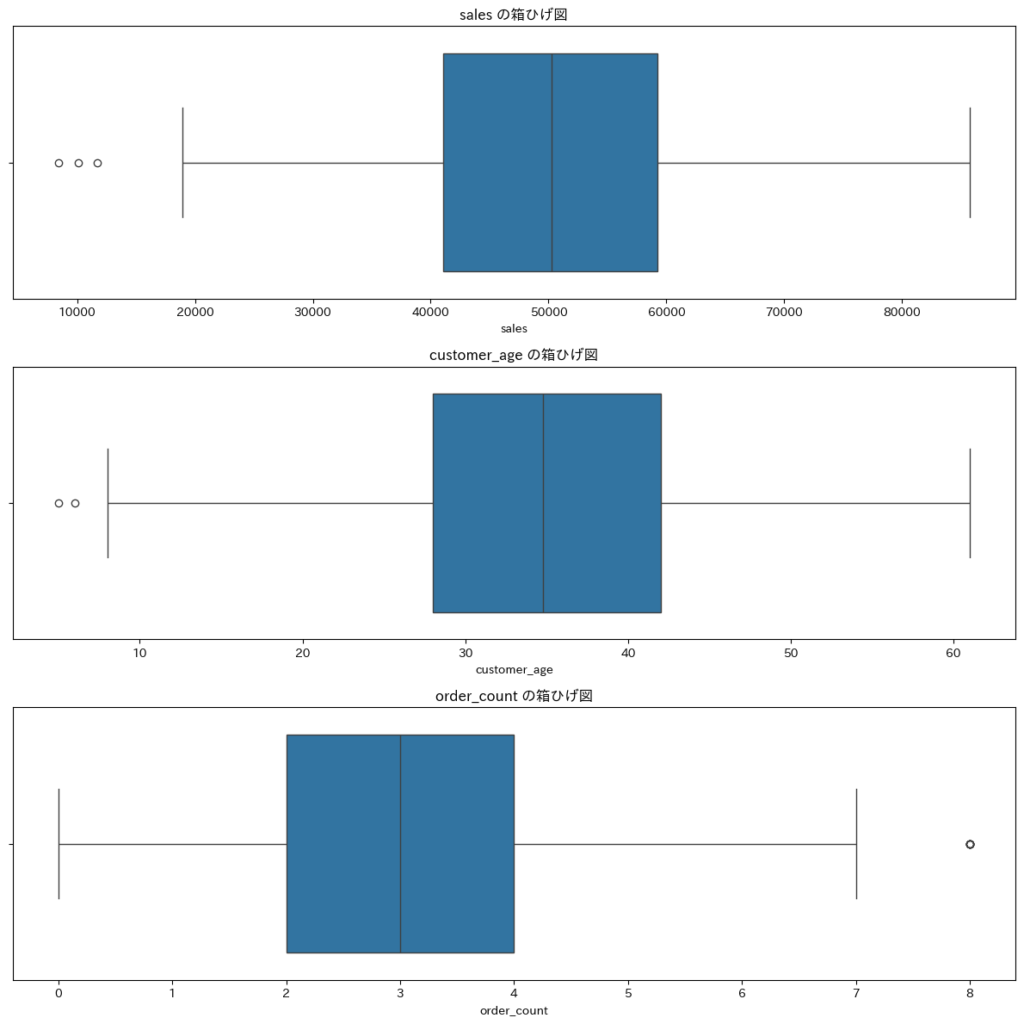
5. 時系列データの分析(必要に応じて)
- 時系列データが含まれている場合は、トレンドや季節性を分析し、適切な特徴量を作成します。
# 時系列データのプロット
data['date'] = pd.to_datetime(data['date'])
data.set_index('date', inplace=True)
plt.figure(figsize=(15, 5))
plt.plot(data['sales'])
plt.title("売上の時系列データ")
plt.xlabel("日付")
plt.ylabel("売上")
plt.show()
まとめ
今回は代表的な分析を行ってデータの基本的な情報を確認してみました。
データ分析はデータの特徴を理解し、問題に合ったモデリングを行うための重要なステップなので、
各種コード例や可視化ツールを使いこなし、データの質を把握することが、MLOpsパイプラインの安定性とモデル精度向上に大きく貢献します。
おすすめの書籍
リンク