【Python_画像処理】CGANでデータを増やしてMNIST100枚から推定精度99%以上を目指す
はじめに
今回は機械学習でおなじみのMNISTで画像の分類をして推定精度99%以上を目指したいと思います。普通にやっても面白くないので使える画像は各クラス100枚ずつ、合計1000枚のみとします。
各クラス100枚ではあまり精度が期待できないので、今回はCGANを使って画像を各クラス100枚から1000枚に増やして学習のためのデータセットを作成したいと思います。
CGANとは
CGANとは【ConditionalGAN】(条件付きGAN, CGAN)といいます。そもそもGANとは生成モデルの一種であり、データから特徴を学習することで、実在しないデータを生成したり、存在するデータの特徴に沿って変換する技術で、乱数から画像を生成することができたりします。CGANはGANの応用で、どのような画像を生成するか条件付きで指定することができるようになります。例えば『1』と指定すると1の画像を自動生成するということができます。
オリジナルのGANとCGANの大きな違いは、Generatorの入力にノイズベクトルだけでなく、条件ベクトルも与えている点です。それに伴い、Discriminatorも条件ベクトルに相当する条件データを入力できるよう改良されています。
CGANの設計はシンプルで、以下の2つのステップを繰り返すことにより、本物らしい条件付きの画像を生成できます。
- 画像とラベルを入力として画像の真偽を判定する識別器の学習
- 指定した条件通りの画像を生成する生成器の学習
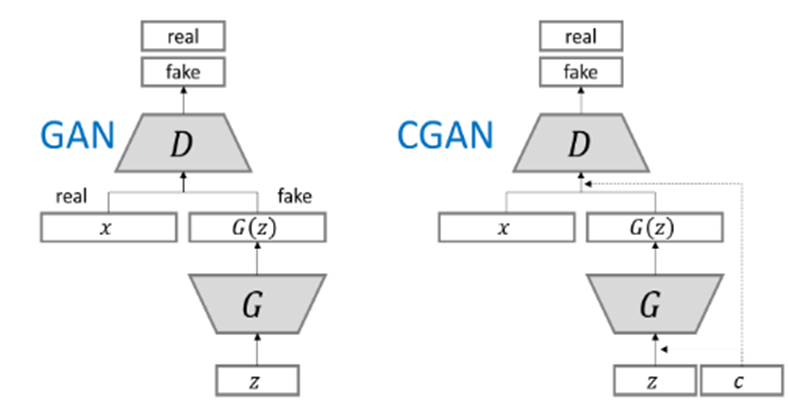
引用:https://github.com/hwalsuklee/tensorflow-generative-model-collections
数字画像を生成するCGANを作成
今回はGoogle Colab上で実装しました。コードは一部抜粋したものを記載しています。
学習用のMNISTのダウンロード
まずはデータセットを作るためのCGANを作っていきます。
今回は各クラス100枚ずつをMNISTから抽出してデータローダーを作成します。
#MNISTのトレーニングデータセットを読み込む
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, ), (0.5, ))])
#MNIST全データ読み込み
dataset = torchvision.datasets.MNIST(root='mnist_root',
train=True,
download=True,
transform=transform)
#各クラス100枚ずつを使用するのでdatasetから抽出する
n_samples =100
idx=[]
for i in range(0,10):
idx.append(np.where(dataset.targets == i)[0][:n_samples])
idx1 = [x for row in idx for x in row]
dataset.data = dataset.data[idx1]
dataset.targets = dataset.targets[idx1]
#データローダーを作成する
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=int(workers))
# 学習に使用するデバイスを得る。可能ならGPUを使用する
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device:', device)CGANのネットワークを定義
生成器(Generator)を定義します。
class Generator(nn.Module):
def __init__(self, nz=100, nch_g=64, nch=1): #nzは入力ベクトルzの次元
super(Generator, self).__init__()
#ネットワーク構造の定義
self.layers = nn.ModuleList([
nn.Sequential(
nn.ConvTranspose2d(nz, nch_g * 8, kernel_size=2, stride=1 ,padding=0), #高さ1×横幅1 → 高さ2×横幅2
nn.BatchNorm2d(nch_g * 8),
nn.ReLU()
),
nn.Sequential(
nn.ConvTranspose2d(nch_g * 8, nch_g * 4, kernel_size=4, stride=2 ,padding=1), #2×2 → 4×4
nn.BatchNorm2d(nch_g * 4),
nn.ReLU()
),
nn.Sequential(
nn.ConvTranspose2d(nch_g * 4, nch_g * 2, kernel_size=4, stride=2 ,padding=1), #4×4 → 8×8
nn.BatchNorm2d(nch_g * 2),
nn.ReLU()
),
nn.Sequential(
nn.ConvTranspose2d(nch_g * 2, nch_g,kernel_size=2, stride=2, padding=1), #8×8 → 14×14
nn.BatchNorm2d(nch_g),
nn.ReLU()
),
nn.Sequential(
nn.ConvTranspose2d(nch_g, nch,kernel_size=4, stride=2, padding=1),#14×14 →28×28
nn.Tanh()
),
])
#順伝播の定義
def forward(self, z):
for layer in self.layers: #layersの各層で演算を行う
z = layer(z)
return z識別器(Discriminator)を定義します。
class Discriminator(nn.Module):
def __init__(self, nch=1, nch_d=64): #nchは入力のチャンネル数
super(Discriminator, self).__init__()
#ニューラルネットワークの構造を定義
self.layers = nn.ModuleList([
nn.Sequential(
nn.Conv2d(nch, nch_d*2, kernel_size=3, stride=3 ,padding=0), #28×28 → 7×7
nn.LeakyReLU(negative_slope=0.2)
),
nn.Sequential(
nn.Conv2d(nch_d*2, nch_d*4,kernel_size=3, stride=1 ,padding=1) ,#7×7 → 7×7
nn.BatchNorm2d(nch_d*4),
nn.LeakyReLU(negative_slope=0.2)
),
nn.Sequential(
nn.Conv2d(nch_d*4, nch_d*8,kernel_size=3, stride=3 ,padding=1), #7×7 → 3×3
nn.BatchNorm2d(nch_d*8),
nn.LeakyReLU(negative_slope=0.2)
),
nn.Conv2d(nch_d*8, 1, kernel_size=3, stride=1 ,padding=0)
])
#順伝播の定義
def forward(self,x): #xは本物画像or贋作画像
for layer in self.layers: #各層で演算を行う
x = layer(x)
return x.squeeze() #不要な次元を削除CGANネットワークの学習
“画像とラベルを入力として画像の真偽を判定する識別器の学習"と
”指定した条件通りの画像を生成する生成器の学習”を繰り返して学習を進めていきます。
#損失関数
criterion = nn.MSELoss() #二乗誤差損失
#criterion = nn.CrossEntropyLoss()
#最適化関数
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999), weight_decay=1e-5)
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999), weight_decay=1e-5)
G_loss_mean = [] #学習全体でのlossを格納するリスト(generator)
D_loss_mean = []
epoch_time = [] #時間の計測結果を格納するリスト
for epoch in range(n_epoch):
start = time.time() #時間の計測を開始
G_losses = [] #1エポックごとのlossを格納するリスト(Generator)
D_losses = []
for itr, data in enumerate(dataloader):
#本物画像のロード
real_image = data[0].to(device) #本物画像をロード
real_label = data[1].to(device) #本物画像のラベルとロード
real_image_label = concat_image_label(real_image, real_label, device) #画像とラベルを連結
#贋作画像生成用のノイズとラベルを準備
sample_size = real_image.size(0) #0は1次元目(バッチ数)を指す
noise = torch.randn(sample_size, nz, 1 ,1, device=device)
fake_label = torch.randint(10, (sample_size,), dtype=torch.long, device=device)
fake_noise_label = concat_noise_label(noise, fake_label, device) #ノイズとラベルを連結
#識別の目標値を設定
real_target = torch.full((sample_size,), 1., device=device) #本物は1
fake_target = torch.full((sample_size,), 0., device=device) #偽物は0
#Discriminator(判別器)の更新
netD.zero_grad() #勾配の初期化
output = netD(real_image_label) #順伝播させて出力(分類結果)を計算
errD_real = criterion(output, real_target) #本物画像に対する損失値
D_x = output.mean().item()
fake_image = netG(fake_noise_label) #生成器Gで贋作画像を生成
fake_image_label = concat_image_label(fake_image, fake_label, device) #贋作画像とラベルを連結
output = netD(fake_image_label.detach()) #判別器Dで贋作画像とラベルの組み合わせに対する識別信号を出力
errD_fake = criterion(output, fake_target) #偽物画像に対する損失値
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake #Dの損失の合計
errD.backward() #誤差逆伝播
optimizerD.step() #Dのパラメータを更新
#Generator(生成器)の更新
netG.zero_grad()
output = netD(fake_image_label) #更新した判別器で改めて判別結果を出力
errG = criterion(output, real_target) #贋作画像を本物と誤認させたいので、目標値はreal_targetの1
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
# lossの保存
G_losses.append(errG.item())
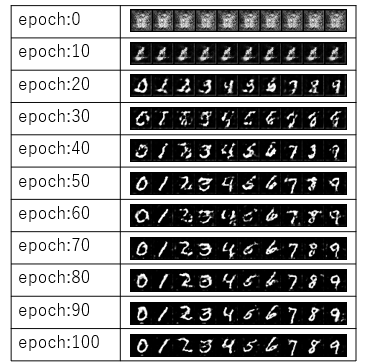
D_losses.append(errD.item())epoch0(学習1回目)ではノイズのような画像が生成されていますが、試行回数が増えるにしたがって0~9の数字がはっきりしていくことがわかります。
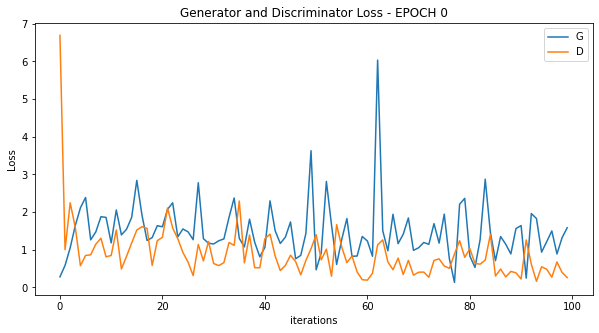
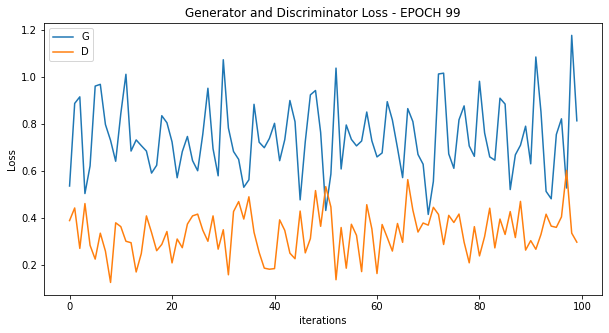
学習のLossを確認すると最初はGeneratorのLossが大きくDiscriminatorに偽物と判定されているが、学習が進むにつれてGeneratorとDiscriminatorのLossはともに小さくなり、差も小さくなっています。
CGANによる画像生成とクラス分類
CGANでクラス指定して画像生成
生成するクラスの定義(0~9)をして、各クラス1000枚ずつ生成し、それぞれのフォルダに保存していきます。
#GANによって文字画像を生成し、学習データ作成
for i in range(10):
outd = './gandata1/'+str(i)
os.makedirs(outd, exist_ok=True)
for l in range(1000):#各クラス1000枚ずつ生成し、それぞれのフォルダに保存していく
fixed_noise = torch.randn(1, nz, 1, 1, device=device) #ノイズの生成
fixed_label = [i] * (1) #生成するクラスの定義(0~9)
fixed_label = torch.tensor(fixed_label, dtype=torch.long, device=device) #torch.longはint64を指す
fixed_noise_label = concat_noise_label(fixed_noise, fixed_label, device) #確認用のノイズとラベルを連結
#確認用画像の生成(1エポックごと)
fake_image = netG(fixed_noise_label)
vutils.save_image(fake_image.detach(), '{}/fake_samples_{:04d}.png'.format(outd, l), normalize=True, nrow=10)#画像保存推論モデルの定義
数字画像のクラス分類を行うモデルを作成します。単純なMLP作成しました。
#MLP作成
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.classifier = nn.Sequential(
# 第1引数:input
# 第2引数:output
nn.Linear(28 * 28, 400),
# メモリを節約
nn.ReLU(inplace=True),
nn.Linear(400, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 100),
nn.ReLU(inplace=True),
nn.Linear(100, 10)
)
def forward(self, x):
output = self.classifier(x)
return output
model = MLP()
criterion = nn.CrossEntropyLoss() #クロスエントロピー誤差
optimizer = optim.Adam(model.parameters(), lr=0.001)#Adam,学習率0.001推論モデルの学習
CGANで作成したデータセットを使って学習させていきます。
num_epochs = 10
losses = []
accs = []
batch_size =10
#生成画像の保存場所
root ='./gandata1'
#テンソル化
transform = transforms.ToTensor()
#データセット作成
images = ImageFolder(root, transform =transform)
#データローダー定義
dataloaderGAN = data.DataLoader(images, batch_size = batch_size, shuffle=True)
for epoch in range(num_epochs):
running_loss = 0.0
running_acc = 0.0
for imgs, labels in dataloaderGAN:
imgs= imgs[:,0,:,:].unsqueeze(1)#ImageFokderは3チャンネルで返されるので1チャンネルのみ使用する
imgs = imgs.contiguous().view(batch_size, -1)#(1,28*28)に1次元化
optimizer.zero_grad()
output = model(imgs)
loss = criterion(output, labels)
running_loss += loss.item()
pred = torch.argmax(output, dim=1)# dim=1 => 0-9の分類方向のMax値を返す
running_acc += torch.mean(pred.eq(labels).float())
loss.backward()
optimizer.step()
# 推定精度計算
running_loss /= len(dataloaderGAN)
running_acc /= len(dataloaderGAN)
losses.append(running_loss)
accs.append(running_acc)
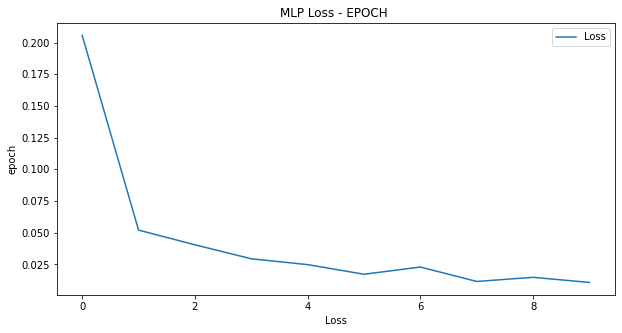
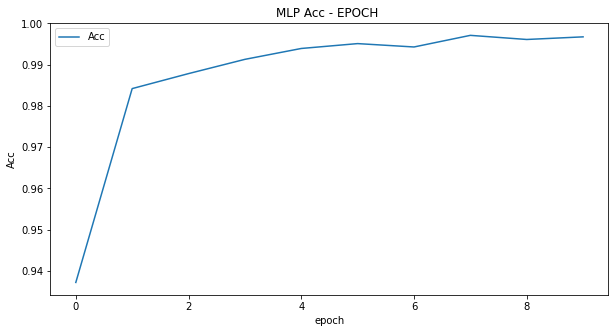
print("epoch: {}, loss: {}, acc: {}".format(epoch, running_loss, running_acc))学習時の損失と推論精度です。学習の3回目ですでに推論精度は99%を超えています。
モデルの精度検証
MNISTのデータを使って推論モデルの精度検証を実施します。
# テスト用のMNISTデータセット
testimages = ImageFolder("./data/test", transform =transform)
dataloader_test = data.DataLoader(images, batch_size = batch_size, shuffle=True)
num_epochs = 1
correct = 0
total = 0
for epoch in range(num_epochs):
model.eval()
with torch.no_grad():
for imgs, labels in dataloader_test:
imgs= imgs[:,0,:,:].unsqueeze(1)#ImageFokderは3チャンネルで返されるので1チャンネルのみ使用する
imgs = imgs.contiguous().view(batch_size, -1)
output = model(imgs)
pred = torch.argmax(output, dim=1) # dim=1 => 0-9の分類方向のMax値を返す
total += labels.size(0)
correct += (pred == labels).sum()#正解数カウント
# 精度計算
print('Accuracy %d / %d = %f' % (correct, total, correct / total))推論精度は99.9%と目標を達成することができました。
Accuracy 10992 / 11000 = 0.999273まとめ
今回はCGANでのデータ生成と数字画像のクラス分類を行いました。データ拡張の手法として回転や縮小、拡大などがありますがGANやCGANを使用することでバリエーションが豊富なデータセットを作成することができました。