MLOps入門:#2 データの取り込みを理解しよう
前回の記事はこちら
はじめに
データの取り込みはMLOpsパイプラインの最初のステップです。
この記事では、具体的なコード例やツールの使用方法も交えて、データの取り込みについて解説していきます。
1. データ取り込みの重要性
パイプライン全体の信頼性を支えるために、データの取り込みの段階で安定的かつ効率的な仕組みを構築することが重要です。
2. データ取り込みの種類とコード例
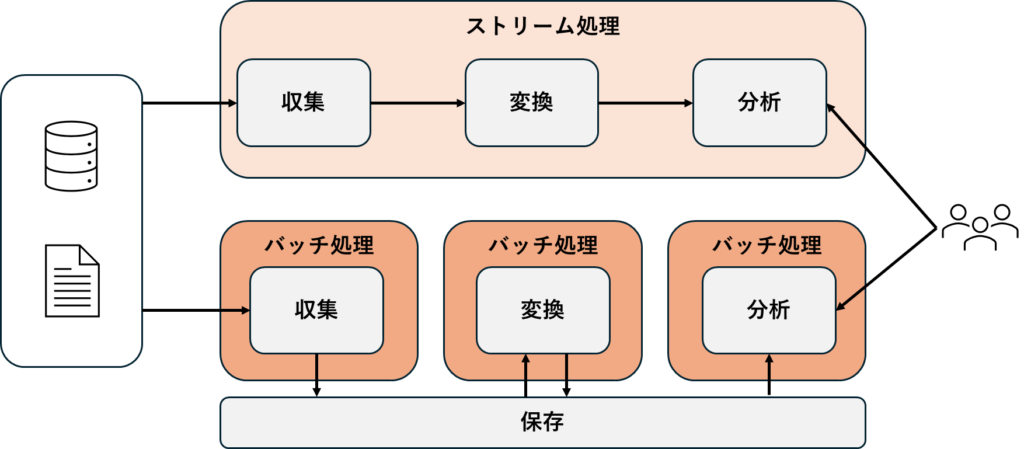
バッチ取り込み
定期的にデータを一括で取り込むケースでは、スケジューラ(例: Apache Airflow)やバッチジョブを使います。
例えば、データベースからの取り込みには以下のPythonコードを使用できます。
import pandas as pd
import sqlalchemy
# データベース接続設定
DATABASE_URI = 'postgresql://user:password@localhost:5432/mydatabase'
engine = sqlalchemy.create_engine(DATABASE_URI)
# データをバッチで取得
def fetch_data():
query = "SELECT * FROM my_table WHERE date > CURRENT_DATE - INTERVAL '1 day'"
data = pd.read_sql(query, engine)
return data
data = fetch_data()
print(data.head())
ストリーミング取り込み
リアルタイムでデータを取り込むケースでは、Apache KafkaやAWS Kinesisのようなストリーミングツールを使います。
Kafkaを使ったPythonでの取り込み例です。
from kafka import KafkaConsumer
import json
# Kafkaコンシューマ設定
consumer = KafkaConsumer(
'my_topic',
bootstrap_servers=['localhost:9092'],
value_deserializer=lambda x: json.loads(x.decode('utf-8'))
)
# ストリーミングデータの取り込み
for message in consumer:
data = message.value
print(data) # データを処理3. データの保存
取り込んだデータは用途や目的に応じて保存先を決めます。
データレイクとデータウェアハウスは、ビッグデータの管理や分析において重要なデータストレージ方法です。
それぞれの特徴を理解し、目的に合わせて使い分けることで、データパイプラインの効率化を図れます。
データレイク
- 構造化・非構造化データを格納可能:テキストや画像、ログデータなど、さまざまなデータ形式をそのまま格納。
- 柔軟性が高い:データを変換せずに保持するため、データサイエンスやAIでの実験がしやすい。
- 低コスト:クラウドベースのデータレイク(例: AWS S3やAzure Data Lake)は、大規模なデータを低コストで保存できる。
データウェアハウス
- 構造化データを保存:SQLのような分析クエリを効率的に実行できる形式で、主に構造化データが対象。
- 高いクエリパフォーマンス:データ分析やBIツールとの連携がしやすく、ビジネスインテリジェンス向けの利用が多い。
- スキーマが固定:データの取り込み時にスキーマが求められるため、信頼性のあるデータが得られる。
データレイクとデータウェアハウスの使い分け
- 探索的な分析やモデリングには、柔軟性が求められるデータレイクが適しています。
- BIやレポーティング、定型分析には、高速なクエリ処理が可能なデータウェアハウスが向いています。
4. データソースの種類とコード例
データベースからのデータ取り込み
SQLデータベースからのデータ取り込みには、Pythonのsqlalchemyとpandasを使用します。
import pandas as pd
from sqlalchemy import create_engine
# データベース接続設定
DATABASE_URI = 'postgresql://user:password@localhost:5432/mydatabase'
engine = create_engine(DATABASE_URI)
# データの取得
def fetch_data():
query = "SELECT * FROM sales_data WHERE date > '2024-01-01'"
data = pd.read_sql(query, engine)
return data
data = fetch_data()
print(data.head())
AWS S3からのデータ取り込み
AWS S3からデータを取得するには、boto3ライブラリを使います。
import boto3
import pandas as pd
# S3クライアント設定
s3_client = boto3.client('s3')
# S3からCSVデータを読み込む関数
def fetch_s3_data(bucket_name, file_key):
response = s3_client.get_object(Bucket=bucket_name, Key=file_key)
data = pd.read_csv(response['Body'])
return data
bucket_name = 'my-s3-bucket'
file_key = 'data/my_data.csv'
data = fetch_s3_data(bucket_name, file_key)
print(data.head())
Web APIからのデータ取り込み
REST APIからデータを取得する場合、Pythonのrequestsライブラリが便利です。
import requests
import pandas as pd
# APIからJSONデータを取得し、DataFrameに変換
def fetch_api_data(api_url):
response = requests.get(api_url)
data = response.json()
df = pd.DataFrame(data)
return df
api_url = 'https://api.example.com/data'
data = fetch_api_data(api_url)
print(data.head())5. データ取り込みで考慮すべきポイント
データの品質チェック
取り込み時に、欠損値や異常値のチェックを自動化します。以下は、欠損値のチェック例です。
# データの品質チェック
def check_data_quality(df):
if df.isnull().sum().any():
print("欠損値が含まれています")
else:
print("データは正常です")
check_data_quality(data)セキュリティとアクセス管理
AWS IAMロールやAPIトークンを利用してアクセス制御を設定し、必要な認証情報を安全に管理します。
6. データ取り込みの自動化
Apache Airflowを使ったスケジュール管理
AirflowのDAG(Directed Acyclic Graph)を使って、定期的なデータ取り込みを自動化できます。
以下は、Airflowでバッチ取り込みを行うDAGの例です。
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
# Airflowで定義するDAG
def fetch_data():
# データベースからデータを取得
# (ここでのfetch_data関数は、上で定義したものを使用)
data = fetch_data()
print(data.head())
dag = DAG('data_ingestion', start_date=datetime(2024, 1, 1), schedule_interval='@daily')
# DAGにタスクを追加
task = PythonOperator(task_id='fetch_data_task', python_callable=fetch_data, dag=dag)
AWS Lambdaを使ったイベント駆動の自動化
AWS Lambdaを使って、S3にファイルがアップロードされるたびに自動でデータ取り込み処理を開始する設定が可能です。
import boto3
import pandas as pd
def lambda_handler(event, context):
# S3からデータを取得
s3_client = boto3.client('s3')
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
response = s3_client.get_object(Bucket=bucket, Key=key)
data = pd.read_csv(response['Body'])
# データ処理(例:表示)
print(data.head())
まとめ
- データの取り込みはMLOpsの基礎であり、効率的で自動化された取り込みフローを構築することで、データの品質とパイプライン全体の信頼性が向上します。
- この自動化によって、後続の工程での作業がスムーズになり、全体の生産性が上がります。
- 次の記事では、データ準備の次のステップである「データ分析」について詳しく見ていきます。