MLOps入門:#4 データ変換をして使いやすい形に整えよう
前回の記事はこちら
はじめに
データ変換は、データをモデルが扱いやすい形式に加工するプロセスです。
欠損値や異常値の処理、カテゴリ変数のエンコーディング、スケーリングなど、さまざまな変換手法があります。
本記事では、データ変換の主な手法と、それぞれの具体的なコード例を紹介します。
これにより、後続のモデリング工程がスムーズになり、モデルの精度も向上します。
データ変換の重要性
モデルの性能は、どれだけ質の高いデータが入力されるかに依存します。
適切なデータ変換を行うことで、モデルがより効率的に学習できるようになります。
特に、データのスケーリングやエンコーディングは、モデルが正確に予測を行うために重要なステップです。
欠損値の処理
欠損値が含まれている場合、それを処理しないとモデルが正しく学習できません。
欠損値とはデータセットにおいて値が存在しない、または記録されていないデータポイントのことを指します。
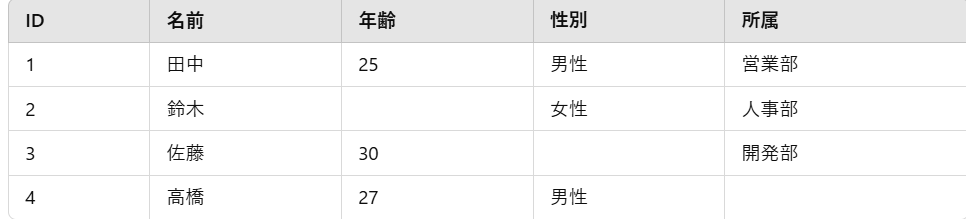
例えば上記では次のような欠損値があります:
- 年齢が2行目で記録されていない
- 性別が3行目で記録されていない
- 所属が4行目で記録されていない
※欠損値をそのまま扱えるモデルもあります
XGBoostやLightGBMなどのモデルは欠損値を直接扱える機能を持っています。この場合、欠損値の処理は不要です。
欠損値の対処方法
欠損値の影響を最小限に抑えるために、適切な方法を選択します。
1. 削除
欠損値が少ない場合や欠損値が含まれるデータが重要でない場合に行います。
# 欠損値を含む行を削除
df_dropped = df.dropna()2. 補完
補完方法はデータの種類や目的に応じて選択します。
平均値や中央値で補完:
# 年齢列を平均値で補完
df['年齢'] = df['年齢'].fillna(df['年齢'].mean())最頻値で補完:
# 性別列を最頻値で補完
df['性別'] = df['性別'].fillna(df['性別'].mode()[0])カテゴリ変数のエンコーディング
カテゴリデータは、そのままではモデルに利用できないため、数値に変換する必要があります。
代表的な手法は、ワンホットエンコーディングとラベルエンコーディングです。
ワンホットエンコーディング
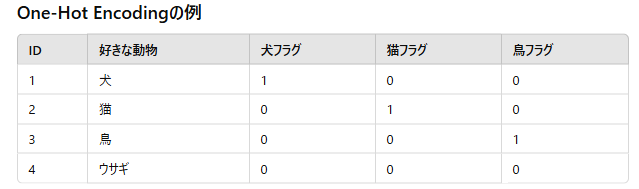
カテゴリ変数を数値化する方法の一つに、「One-Hot Encoding」という手法があります。これは「ダミー変数化」とも呼ばれ、各カテゴリごとに新しいフラグ変数を作成し、該当する場合は1、該当しない場合は0を設定する方法です。
例えば、「好きな動物」というデータがあり、選択肢として「犬」「猫」「鳥」「ウサギ」が含まれているとします。
この場合、新たに「好きな動物が犬フラグ」「好きな動物が猫フラグ」「好きな動物が鳥フラグ」を作成し、各データに対して該当する動物のフラグを1、それ以外を0とします。もし「ウサギ」が選ばれた場合は、作成したフラグ変数がすべて0となることで表現できます。
この手法には、カテゴリの数が多い場合に作成される変数が増え、データの横幅が大きくなる点や、多くの値が0となるスパースなデータになる点がデメリットとして挙げられます。
import pandas as pd
# サンプルデータの作成
data = pd.DataFrame({
'ID': [1, 2, 3, 4],
'好きな動物': ['犬', '猫', '鳥', 'ウサギ']
})
# One-Hot Encodingの実施
encoded_data = pd.get_dummies(data, columns=['好きな動物'], prefix='動物')
# 結果の表示
print(encoded_data)ラベルエンコーディング
カテゴリ変数を数値化する方法の一つに、「ラベルエンコーディング」があります。これは、各カテゴリに固有の整数値を割り当てる手法です。例えば、「犬」「猫」「鳥」「ウサギ」というカテゴリデータがある場合、それぞれに 0, 1, 2, 3 などの数値を割り当てます。
この手法の利点として、データの次元が増えないため、One-Hot Encodingと比べて省メモリで扱える点があります。ただし、カテゴリの順序がない場合でも数値に順序があるように解釈される可能性があるため、モデルによっては適切に扱えないことがあります。

import pandas as pd
from sklearn.preprocessing import LabelEncoder
# サンプルデータの作成
data = pd.DataFrame({
'ID': [1, 2, 3, 4],
'好きな動物': ['犬', '猫', '鳥', 'ウサギ']
})
# ラベルエンコーディングの適用
le = LabelEncoder()
data['動物ラベル'] = le.fit_transform(data['好きな動物'])
# 結果の表示
print(data)数値データのスケーリング
機械学習モデルでは、異なるスケールの特徴量を含むデータをそのまま使用すると、学習の効率が悪くなったり、特定の特徴量が他よりも影響を持ちすぎたりする可能性があります。そのため、特徴量のスケーリング(標準化や正規化)を行うことで、モデルの精度を向上させることができます。
例えば、以下のようなデータがあるとします。
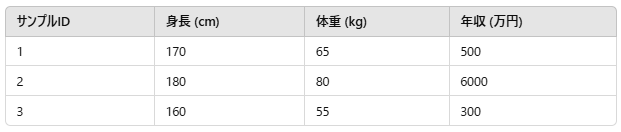
この場合、「身長」と「体重」の値の範囲は数十〜百程度ですが、「年収」は数百〜数千と大きく異なります。多くの機械学習モデル(特に勾配降下法を使用する線形回帰やニューラルネットワークなど)は、特徴量のスケールが異なると学習がうまく進まないことがあります。
標準化
標準化とは、データを 平均0、分散1 の標準正規分布に変換する手法です。
一般的に、以下の式で計算されます。

# 標準化の適用
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)正規化
正規化とは、データを 0〜1の範囲 に収める手法です。
一般的に 最小最大スケーリング(Min-Max Scaling) を使用し、以下の式で計算します。
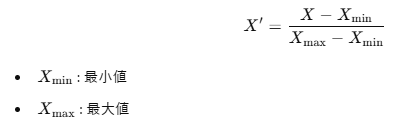
# 正規化の適用
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data)