【論文】Point2Vec for Self-Supervised Representation Learning on Point Clouds
※ただの翻訳とポイントを書いたメモです。正確性は保証していません。
https://arxiv.org/pdf/2303.16570v1.pdf
アブスト
近年自己教師付き学習フレームワークであるdata2vecは、マスクされた学生-教師アプローチを使用して様々なモダリティに対して鼓舞的なパフォーマンスを示しています。
しかし、このフレームワークが3Dポイントクラウドのユニークな課題に対して一般化するかどうかは未解明です。
この問いに答えるために、私たちはdata2vecをポイントクラウド領域に拡張し、いくつかのダウンストリームタスクで励ましい結果を報告します。詳細な分析により、位置情報の漏洩が全体的なオブジェクト形状を学生に明らかにし、重度のマスキング下でもポイントクラウドの強力な表現を学習するdata2vecを妨げることを発見しました。
私たちはこの3D特有の欠点を解決するために、ポイントクラウド上でのdata2vecのような事前学習の全力を発揮するpoint2vecを提案します。私たちの実験では、point2vecがModelNet40とScanObjectNNでの形状分類と少数ショット学習において他の自己教師付き方法を上回り、ShapeNetPartsでの部分セグメンテーションにおいて競争力のある結果を達成していることを示しています。
これらの結果は、学習された表現が強力で転送可能であることを示しており、point2vecを自己教師付きのポイントクラウド表現学習の有望な方向性として強調しています。
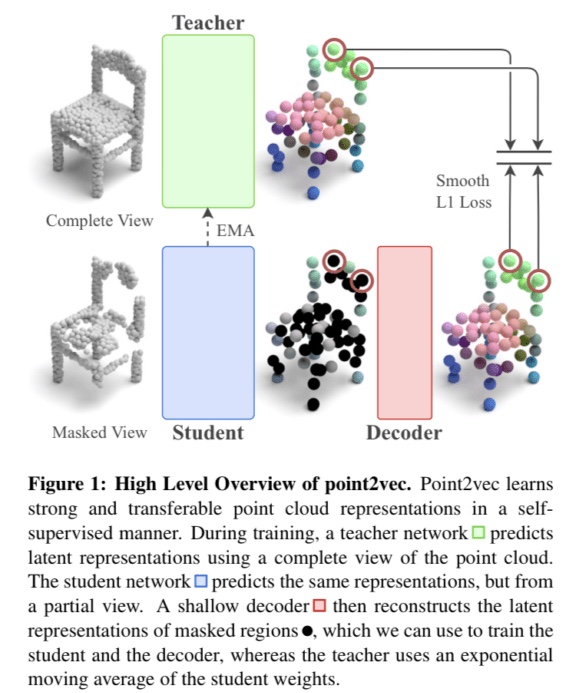
ポイント
- この研究では、自己教師付き表現学習フレームワークであるdata2vecを3Dポイントクラウドに適用することを試みています。
- しかし、data2vecの学習において、位置情報の漏洩が全体的なオブジェクト形状を学生に明らかにし、ポイントクラウドの強力な表現を学習することを妨げることが発見されました。
- これを解決するために、研究者たちは新たなフレームワーク、point2vecを提案しています。これは、3Dポイントクラウド上での自己教師付き事前学習を最大限に活用することを目指しています。
- 実験結果では、point2vecが形状分類と少数ショット学習において他の自己教師付き方法を上回り、部分セグメンテーションにおいて競争力のある結果を達成しています。
- これらの結果は、学習された表現が強力で転送可能であることを示しており、point2vecを自己教師付きのポイントクラウド表現学習の有望な方向性として強調しています。